|
Jiaxin Ge I am a Ph.D. student in computer science at UC Berkeley, advised by Prof. Trevor Darrell. I am a member of Berkeley AI Research (BAIR). I received Bachelor's Degree from Peking University, where I was fortunately advised by Prof. Shanghang Zhang. I also worked closely with Prof. Graham Neubig, Prof. Jim Glass, and Prof. Guangyu Robert Yang. |

|
Selected PublicationsI'm interested in vision-language, agents, vision/video understanding and beyond. If you are interested, please feel free to reach out! |
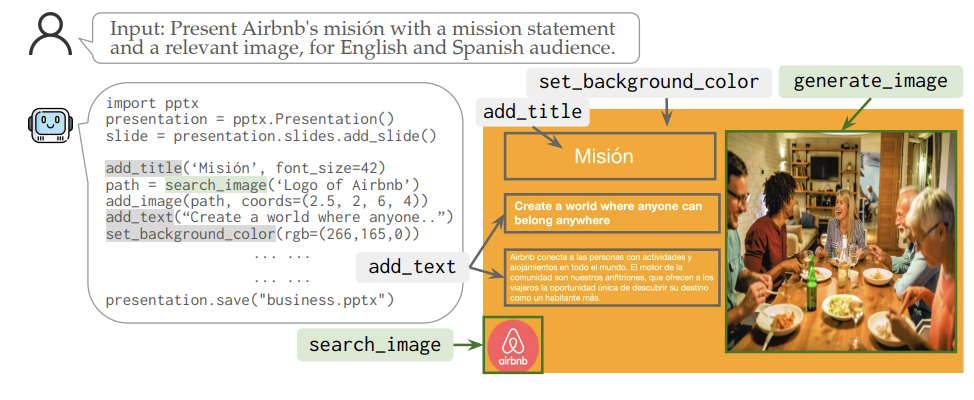 |
Jiaxin Ge*, Zora Zhiruo Wang*, Xuhui Zhou, Yi-Hao Peng, Sanjay Subramanian, Qinyue Tan, Maarten Sap, Alane Suhr, Daniel Fried, Graham Neubig, Trevor Darrell CVPR, 2025 abstract / pdf / code Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals. |
 |
Jiaxin Ge*, Xueying Jia*, Vijay Viswanathan, Hongyin Luo, Graham Neubig preprint, 2024 abstract / pdf / code One of the most reliable ways to create deployable models for specialized tasks is to obtain an adequate amount of high-quality task-specific data. However, for specialized tasks, often such datasets do not exist. Existing methods address this by creating such data from large language models (LLMs) and then distilling such knowledge into smaller models. However, these methods are limited by the quality of the LLMs output, and tend to generate repetitive or incorrect data. In this work, we present Retrieval Based Distillation (ReBase), a method that first retrieves data from rich online sources and then transforms them into domain-specific data. This method greatly enhances data diversity. Moreover, ReBase generates Chain-of-Thought reasoning and distills the reasoning capacity of LLMs. We test our method on 4 benchmarks and results show that our method significantly improves performance by up to 7.8% on SQuAD, 1.37% on MNLI, and 1.94% on BigBench-Hard. |
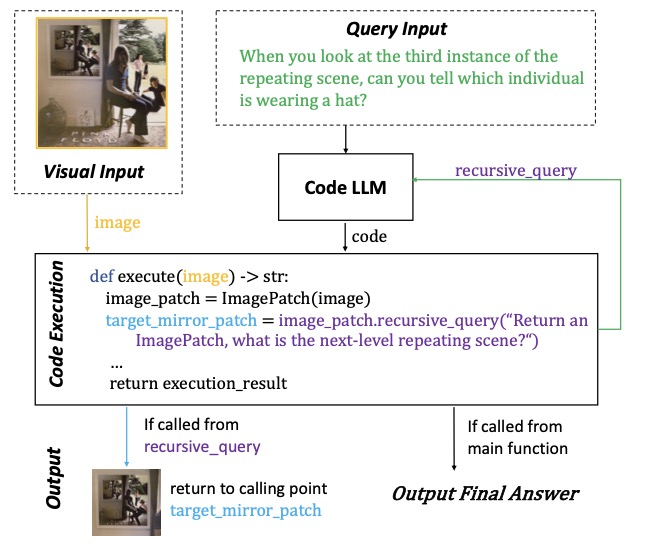 |
Jiaxin Ge, Sanjay Subramanian, Baifeng Shi, Roei Herzig, Trevor Darrell ECCV, 2024 abstract / pdf / code Visual Programming (VP) has emerged as a powerful framework for Visual Question Answering (VQA). By generating and executing bespoke code for each question, these methods demonstrate impressive compositional and reasoning capabilities, especially in few-shot and zero-shot scenarios. However, existing VP methods generate all code in a single function, resulting in code that is suboptimal in terms of both accuracy and interpretability. Inspired by human coding practices, we propose Recursive Visual Programming (RVP), which simplifies generated routines, provides more efficient problem solving, and can manage more complex data structures. RVP is inspired by human coding practices and approaches VQA tasks with an iterative recursive code generation approach, allowing decomposition of complicated problems into smaller parts. Notably, RVP is capable of dynamic type assignment, i.e., as the system recursively generates a new piece of code, it autonomously determines the appropriate return type and crafts the requisite code to generate that output. We show RVP's efficacy through extensive experiments on benchmarks including VSR, COVR, GQA, and NextQA, underscoring the value of adopting human-like recursive and modular programming techniques for solving VQA tasks through coding. |
 |
Tianhua Zhang*, Jiaxin Ge*, Hongyin Luo*, Yung-Sung Chuang, Mingye Gao, Yuan Gong, Xixin Wu, Yoon Kim, Helen Meng, Jim Glass NAACL, 2024 abstract / pdf / code How can we perform computations over natural language representations to solve tasks that require symbolic and numeric reasoning? We propose natural language embedded programs (NLEP) as a unifying framework for addressing math/symbolic reasoning, natural language understanding, and instruction following tasks. Our approach prompts a language model to generate full Python programs that define functions over data structures which contain natural language representations of structured knowledge. A Python interpreter then executes the generated code and prints the output. Despite using a task-general prompt, we find that this approach can improve upon strong baselines across a range of different tasks including math and symbolic reasoning, text classification, question answering, and instruction following. We found that the generated programs are interpretable since they outline the exact reasoning process followed by the program interpreter. |
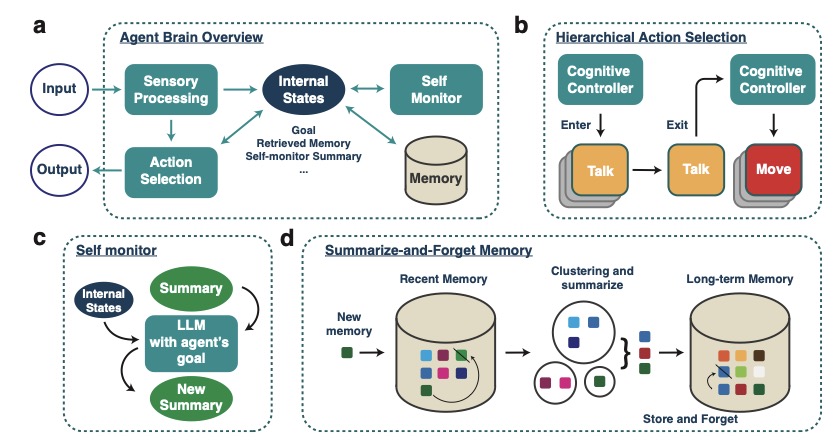 |
Zhao Kaiya, Michelangelo Naim, Jovana Kondic, Manuel Cortes, Jiaxin Ge, Shuying Luo, Guangyu Robert Yang, Andrew Ahn preprint, 2023 abstract / pdf Highly autonomous generative agents powered by large language models promise to simulate intricate social behaviors in virtual societies. However, achieving real-time interactions with humans at a low computational cost remains challenging. Here, we introduce Lyfe Agents. They combine low-cost with real-time responsiveness, all while remaining intelligent and goal-oriented. Key innovations include: (1) an option-action framework, reducing the cost of high-level decisions; (2) asynchronous self-monitoring for better self-consistency; and (3) a Summarize-and-Forget memory mechanism, prioritizing critical memory items at a low cost. We evaluate Lyfe Agents' self-motivation and sociability across several multi-agent scenarios in our custom LyfeGame 3D virtual environment platform. When equipped with our brain-inspired techniques, Lyfe Agents can exhibit human-like self-motivated social reasoning. For example, the agents can solve a crime (a murder mystery) through autonomous collaboration and information exchange. Meanwhile, our techniques enabled Lyfe Agents to operate at a computational cost 10-100 times lower than existing alternatives. Our findings underscore the transformative potential of autonomous generative agents to enrich human social experiences in virtual worlds. |
 |
Jiaxin Ge, Sanjay Subramanian, Trevor Darrell, Boyi Li EMNLP, 2023 abstract / pdf / code Addressing the challenge of adapting pre-trained vision-language models for generating insightful explanations for visual reasoning tasks with limited annotations, we present ReVisE: a cursive ual xplanation algorithm. Our method iteratively computes visual features (conditioned on the text input), an answer, and an explanation, to improve the explanation quality step by step until the answer converges. We find that this multi-step approach guides the model to correct its own answers and outperforms single-step explanation generation. Furthermore, explanations generated by ReVisE also serve as valuable annotations for few-shot self-training. Our approach outperforms previous methods while utilizing merely 5% of the human-annotated explanations across 10 metrics, demonstrating up to a 4.2 and 1.3 increase in BLEU-1 score on the VCR and VQA-X datasets, underscoring the efficacy and data-efficiency of our method. |
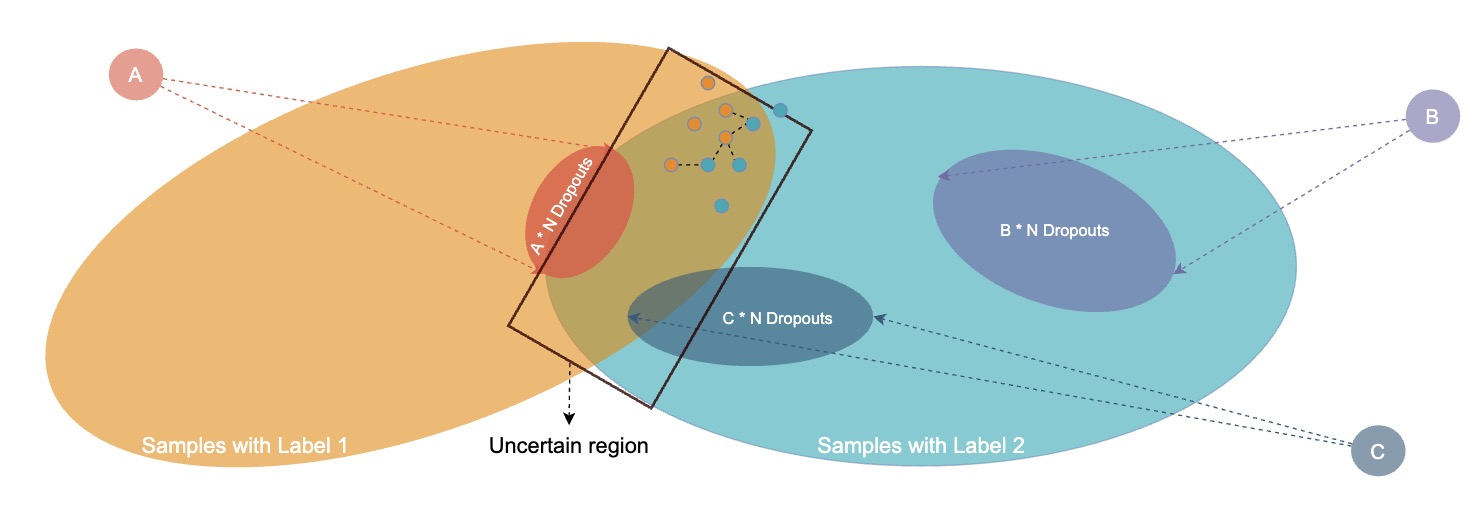 |
Jiaxin Ge*, Hongyin Luo*, Yoon Kim, Jim Glass ACL, 2023 abstract / pdf / code Entailment has been recognized as an important metric for evaluating natural language understanding (NLU) models, and recent studies have found that entailment pretraining benefits weakly supervised fine-tuning. In this work, we design a prompting strategy that formulates a number of different NLU tasks as contextual entailment. This approach improves the zero-shot adaptation of pretrained entailment models. Secondly, we notice that self-training entailment-based models with unlabeled data can significantly improve the adaptation performance on downstream tasks. To achieve more stable improvement, we propose the Simple Pseudo-Label Editing (SimPLE) algorithm for better pseudo-labeling quality in self-training. We also found that both pretrained entailment-based models and the self-trained models are robust against adversarial evaluation data. Experiments on binary and multi-class classification tasks show that SimPLE leads to more robust self-training results, indicating that the self-trained entailment models are more efficient and trustworthy than large language models on language understanding tasks. |
|
|